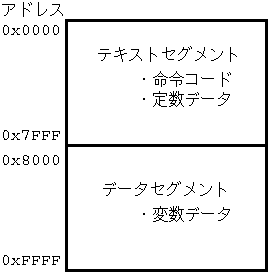
Fig.1 メモリセグメントの配置例
C言語には,3種類の文字列がある. 文字列定数/文字配列/文字列ポインタの違いと使い分けについて理解しよう.
まず,文字列の使い方の間違いの例として,List 1 を実行してみよう. このプログラムでは, 文字列から1文字だけ変更し別の文字列を作ろうとしており, これを少しだけ異なる2通りの方法で試している.
main()
{
char a[] = "data"; // 元の文字列#1(文字配列を文字列定数で初期化)
char *p; // 文字列ポインタ
// 文字列の書き換え #1
printf("\n[1回目の書き換え]\n");
printf("0x%0X : \"%s\"\n", a, a);
p = a; // 文字配列 a[] のアドレスを代入
printf("0x%0X : p = 0x%08X --> \"%s\"\n", &p, p, p);
p[3] = 'e'; // "data" を "date" に書き換え
printf("0x%0X : p = 0x%08X --> \"%s\"\n", &p, p, p);
// 文字列の書き換え #2
printf("\n[2回目の書き換え]\n");
printf("0x%0X : \"%s\"\n", "text", "text");
p = "text"; // 文字列定数 "text" のアドレスを代入
printf("0x%0X : p = 0x%08X --> \"%s\"\n", &p, p, p);
p[0] = 'n'; // "text" を "next" に書き換え
printf("0x%0X : p = 0x%08X --> \"%s\"\n", &p, p, p);
}
実行例:
[1回目の書き換え] 0xEC377150 : "data" 0xEC377148 : p = 0xEC377150 --> "data" # p は配列 a[] を参照 0xEC377148 : p = 0xEC377150 --> "date" # メモリ内容が書き換えられた [2回目の書き換え] 0x00400741 : "text" 0xEC377148 : p = 0x00400741 --> "text" # p は定数 "text" を参照 Segmentation fault # 書き換えに失敗 または Bus error # 書き換えに失敗
どちらの方法でも,1文字を書き換える処理は同じに見えるが, 2番目の方法では実行時エラーによって強制終了されてしまった. この segmentation fault(セグメントエラー)や bus error(バスエラー)は, 処理系のメモリ保護機能によって発生する.
Table 1 は,この実行例におけるメモリマップ表である.
| アドレス範囲 | 変数名 | 初期値 | → #1 後の値 | → #2 後の値 |
|---|---|---|---|---|
| 0x 0040 0741 | 't' | 't' | → 't' (書き換え失敗) |
|
| 0x 0040 0742 | 'e' | 'e' | 'e' | |
| 0x 0040 0743 | 'x' | 'x' | 'x' | |
| 0x 0040 0744 | 't' | 't' | 't' | |
| 0x 0040 0745 | '\0' | '\0' | '\0' | |
| 大きな隔たり |
空き領域など | |||
| 0x EC37 7148 - 714F | p | ゴミ | → 0x EC37 7150 (a の先頭アドレス) |
→ 0x 0040 0741 ("text" の先頭アドレス) |
| 0x EC37 7150 | a[0] | 'd' | 'd' | 'd' |
| 0x EC37 7151 | a[1] | 'a' | 'a' | 'a' |
| 0x EC37 7152 | a[2] | 't' | 't' | 't' |
| 0x EC37 7153 | a[3] | 'a' | → 'e' (書き換え成功) |
'e' |
| 0x EC37 7154 | a[4] | '\0' | '\0' | '\0' |
前回までのメモリマップと何が違うのだろうか? 次の2点に注目しよう:
えー?ポインタ参照 p[i] とかでも配列要素にアクセスできたのでは? だから,変数 p[0], p[1], ..., p[4] が存在するのでは?
いや,実際には,p という変数(ポインタ)は存在するが, p[i] という変数が存在するわけではない. p[i] は,それ自身がデータを記憶しているわけではなく, 単に,他の場所(p が記憶しているアドレスから数えて i 番目の領域) にあるデータを指し示しているだけだ. したがって,変数 p[i] は存在しない.
前回までのメモリマップでは, 変数名が割り当てられたメモリ領域だけを考えれば十分だった. しかし実は,今回のように,無名のメモリ領域もあるんだ.
メモリに記録されているデータとして, 前回までは変数だけしか考えてこなかった. しかし,プログラムの実行中には,実は, 変数以外の無名のデータもメモリに記録されている.
メモリ空間は複数のセグメント(segment,区画)に分けられており, 大まかには次の 2 つに分類される:
メモリマップにおけるセグメントの配置例を Fig.1 に示す.
ちなみに,プログラムを実行するということは, CPU が次のような動作を繰り返すということだ:
では,この知識を踏まえて,前節の List 1 の実行結果の謎について解説しておく. データセグメントに記録されている文字配列 a[] の内容 "data" を書き換えただけなら無事であった. しかし,テキストセグメントに記録されいる文字列定数 "text" までも書き換えようとしたため, メモリ保護機能が作動してしまったのだ.
文字列定数は次のような性質をもつ:
"string" // 複数の文字からなる文字列 "a" // 1 文字だけど...これも文字列(文字ではない) "" // 0 文字だけど...これも文字列
これもまた,文字配列の値(配列名の値)と同じことだ. 配列とアドレスの関係を再確認しよう. (文字列定数も配列名もどちらもアドレスなので, 配列名を文字列定数に置き換えて考えよう.)
たとえば,文字列定数 "string" の n 文字目を取り出すために, 次のようなソースコードを記述してもよいことになる. (無意味なので,ふつうはやらないが...)
"string"[1] // 文字 't' "string"+2 // 文字 'r'
これらを確認するためのプログラムを List 2 に示す.
main()
{
char c;
int i;
printf("\"%s\" = 0x%08X\n", "pineapple", "pineapple");
for (i = 0; i < 10; i++) {
c = "pineapple"[i];
printf("\"pineapple\"[%d] = '%c' = %4d\n", i, c, c);
}
printf("\n");
printf("\"%s\" = 0x%08X\n", "apple", "apple");
for (i = 0; i < 10; i++) {
c = "apple"[i];
printf("\"apple\"[%d] = '%c' = %4d\n", i, c, c);
}
}
実行例:
"pineapple" = 0x004006A0 # テキストセグメント内のアドレス(のハズ) "pineapple"[0] = 'p' = 112 # 配列と同様,[i] で i 文字目 "pineapple"[1] = 'i' = 105 "pineapple"[2] = 'n' = 110 "pineapple"[3] = 'e' = 101 "pineapple"[4] = 'a' = 97 "pineapple"[5] = 'p' = 112 "pineapple"[6] = 'p' = 112 "pineapple"[7] = 'l' = 108 "pineapple"[8] = 'e' = 101 "pineapple"[9] = '' = 0 # 終端記号 "apple" = 0x004006D7 # これもテキスト内だが異なる場所 "apple"[0] = 'a' = 97 "apple"[1] = 'p' = 112 "apple"[2] = 'p' = 112 "apple"[3] = 'l' = 108 "apple"[4] = 'e' = 101 "apple"[5] = '' = 0 # 終端記号 "apple"[6] = '"' = 34 # 以下,他のデータやゴミ "apple"[7] = 'a' = 97 "apple"[8] = 'p' = 112 "apple"[9] = 'p' = 112
テキストセグメントは書き換え不可能なので, 異なる文字列定数は異なるメモリ領域に記録されている.
複数の char 型変数を連続的に並べたものが 文字配列である. 文字配列を宣言すると,データセグメントの中に連続的なアドレスが確保される. 宣言と同時であれば,文字列の代入(初期化)も可能である:
char str[] = "string"; // 宣言と同時に文字配列を初期化.
ところで,このコードは, 前節の文字列定数の性質とは矛盾しているように見える. しかし,このコードは,例外的に正しい. 右辺の文字列定数 "string" の値はアドレスなので, 左辺はポインタ(アドレスを記録する変数)でなければならないハズである. (配列は複数の変数の集合体であって,それ自体は単独の変数ではない.) 本来,文字配列の初期化については,次のようにすべきだろう:
char str[] = { 's', 't', 'r', 'i', 'n', 'g', '\0'}; // 本来の書き方
しかし,これは面倒すぎる. そのため,上記のような例外措置が設けられているわけだ.
なお,この例外措置は,宣言時以外では無効であることに注意しよう:
char str[7];
str = "string"; // 宣言の後に代入.間違い
このコードは, 定数(配列のアドレス)に定数(文字列のアドレス)を代入しようとしており, コンパイルエラーとなる. 本来は,要素毎に 1 文字ずつ代入しなければならない:
char str[7];
str[0] = 's'; str[1] = 't'; str[2] = 'r';
str[3] = 'i'; str[4] = 'n'; str[5] = 'g';
str[6] = '\0'; // 正しいが,面倒
しかし,これではあまりにも不便なので, strcpy() 関数を利用するとよいだろう:
char str[7];
strcpy(str, "string"); // これが正解.楽ちん
List 3 は,文字配列がどのように記録されるのかを確認するためのプログラムである. List 2 のコードおよび実行結果と比較せよ.
main()
{
char str[10]; // 文字配列の宣言
char c;
int i;
strcpy(str, "pineapple"); // 文字配列への代入
printf("str = 0x%08X : \"%s\"\n", str, str);
for (i = 0; i < 10; i++) {
c = str[i];
printf("str[%d] = '%c' = %4d\n", i, c, c);
}
printf("\n");
strcpy(str, "apple");
printf("str = 0x%08X : \"%s\"\n", str, str);
for (i = 0; i < 10; i++) {
c = str[i];
printf("str[%d] = '%c' = %4d\n", i, c, c);
}
}
実行例:
str = 0x4D0E0BD0 : "pineapple" # データセグメント内のアドレス(のハズ) str[0] = 'p' = 112 str[1] = 'i' = 105 str[2] = 'n' = 110 str[3] = 'e' = 101 str[4] = 'a' = 97 str[5] = 'p' = 112 str[6] = 'p' = 112 str[7] = 'l' = 108 str[8] = 'e' = 101 str[9] = '' = 0 str = 0x4D0E0BD0 : "apple" # 同じアドレスに上書き str[0] = 'a' = 97 str[1] = 'p' = 112 str[2] = 'p' = 112 str[3] = 'l' = 108 str[4] = 'e' = 101 str[5] = '' = 0 str[6] = 'p' = 112 # 以下,ゴミ str[7] = 'l' = 108 str[8] = 'e' = 101 str[9] = '' = 0
ひとつの文字配列 str に2回, それぞれ異なる文字列を代入しているので, 異なる文字列が同じメモリ領域に記録(上書き)されている.
文字列ポインタは, 文字列のアドレスを記録するための変数である. 参照先は,文字列定数でも文字配列でも,どちらでもよい. List 1 および Table 1 へ振り返り, ポインタ p の使用方法と値変化を再び観察してみるとよい.
ところで,文字列ポインタと文字配列は, どちらも文字列を取り扱うための変数ではあるが, 互いに異なるものであることに注意せよ. 以下,文字列ポインタの初期化について,紛らわしい事例を列挙しておく.
char *str1 = "string"; // 宣言と同時に代入 char *str2; str2 = "string"; // 宣言した後に代入
char *str; // 初期値はゴミ.つまり参照先不明なので... strcpy(str, "string"); // 間違い
char ary[10]; // データ領域を確保し... char *ptr; ptr = ary; // 記録先を明示しているので... strcpy(ptr, "string"); // 正しい
今回,レポートの必要はないが, 以下の問題に必ず取り組むこと.
次のコードの Q1〜Q6 では, "pineapple" を "apple" に 書き換えようとしている. それぞれについて,うまく行くかどうか? 失敗の原因は何か?説明せよ.
main() {
char *ptr = "pineapple";
char ary[] = "pineapple";
// 書き換え前のデータ
printf("ptr = 0x%08X ==> %s\n", ptr, ptr);
printf("ary = %s\n", ary);
// 問題のコード(Q1 ~ Q7 のコードを記入)
...
// 書き換え後のデータ
printf("ptr = 0x%08X ==> %s\n", ptr, ptr);
printf("ary = %s\n", ary);
}
ptr = "apple"; // Q1
ary = "apple"; // Q2
strcpy(ary, "apple"); // Q3
strcpy(ptr, "apple"); // Q4
ptr = ary; strcpy(ptr, "apple"); // Q5
"pineapple" = "apple"; // Q6
次のコードには不具合がある. それは何か?説明せよ.
char str[] = "apple"; strcpy(str, "pineapple"); // Q7
(c) 2015, yanagawa@kushiro-ct.ac.jp