Fig.1. コンパイラの動作の概要
これまでに作ってきたプログラムは, コンパイルの結果,問題なく動作していた(ハズだ)が, コンパイル時に多数の警告 (warning) が発生していた. つまり,「動くプログラム」ではあったが, 実は,「正しいプログラム」とは言えないものだった.
今回は,Cコンパイラの動作について理解し, 正しいプログラムへ近付いて行こう.
Fig.1 は,これまでのコンパイル作業のイメージ図である. コンパイラ cc を実行すると, ソースファイル1個から プログラムファイル1個が生成されていた.
しかし,実際のコンパイラの動作は,もう少し複雑であり, これからは Fig.2 のようにイメージしよう. 実は,複数のファイル(ソースファイル等)から1個のプログラムを生成している.
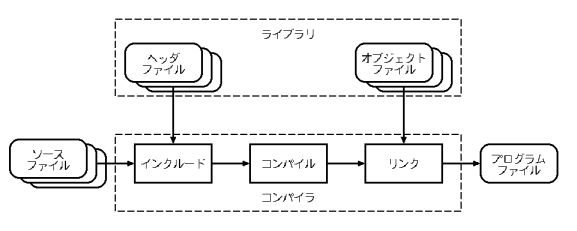
コンパイラ cc を実行すると,内部的には, 次の3段階の処理が実行される:
以下,それぞれの構成要素について,詳しく見て行こう.
変数を使う場合には,変数の型を事前に宣言しなければならなかった. たとえば:
... {
int i; // 変数 i を宣言「このブロック内で int 型の変数 i を使うよ」
for (i = 0; ... ) { // 変数 i を実際に使用
...
}
...
}
変数と同様に,関数を使う場合にも, これまでは省略してきたが, 実は,関数の型を宣言しなければならない.
また,関数の場合には,関数の型(戻り値の型)だけでなく, 引数の型の宣言も必要である. これらは,関数のプロトタイプ宣言と呼ばれている. プロトタイプ宣言を含むソースファイルの構成例を List 1 に示す.
double inv(double x); // 関数のプロトタイプ宣言(呼び出しより前に必要) main() { double x, y; printf("実数 > "); scanf("%lf", &x); // 実数の入力 y = inv(x); // 関数の呼び出し printf("逆数:%f\n", y); } /* x の逆数 */ double inv(double x) // 関数の定義 { return (1.0/x); }
まず,このままコンパイルして,実行できることを確認しよう.
その後,プロトタイプ宣言の行を削除 or コメント化してから, 再度,コンパイルしてみよう. コンパイルエラーとなるハズだ.
次に,List 2 のように書き換えてから,またコンパイルしてみよう. 今度はうまく行くハズだ.
//double inv(double x);// 関数のプロトタイプ宣言 /* x の逆数 */ double inv(double x) // 関数の定義 & プロトタイプ宣言 { return (1.0/x); } main() { ... y = inv(x); ... }
つまり,関数の定義がその呼び出しよりも前に書かれている場合には, プロトタイプ宣言を書く必要はない. この場合は,定義自身が宣言を兼ねることになる.
List 2 は,これまでに使って来たスタイルだ. このスタイルでも,定義とは別に, プロトタイプ宣言の文を追加しても問題ない:
double func(...); // 宣言(不要だが,あってもよい)
double func(...) // 定義
{
...
}
↑ しかし,ほぼ同じコードを2回も書くのは無駄なので,やめよう. 宣言と定義とを1回にまとめるべきだ.
なお,書き順だけで済むなら,プロトタイプ宣言なんて必要ねーだろって? いや必要だ. 次のように,書き順だけでは解決不可能な状況もありえる:
double func1(...); // 宣言(必要ない)
double func2(...); // 宣言(必要)
double func1(...)
{
...
func2(...);
...
}
double func2(...)
{
...
func1(...);
...
}
↑ 宣言がない場合,どっちを先に定義すべきなんだー?
なお,関数のプロトタイプ宣言は, List 1 のようなグローバル宣言の代わりに, 次のようなローカル宣言であっても問題ない:
main()
{
...
double inv(double x);
...
}
その他,暗黙の型宣言(教科書 pp.88-89) によって宣言が不要な場合もあるが, これからは必ず,プロトタイプを意識しよう.
関数には,ソースファイル中で定義する「ユーザ関数」の他に, 事前に定義されている「ライブラリ関数」がある. プロトタイプ宣言は,ユーザ関数だけでなく, ライブラリ関数を呼び出す場合にも必要である.
ただし,ライブラリ関数のプロトタイプ宣言については, ソースファイル内に,いちいち記述する必要はない. 大抵のライブラリには, プロトタイプ宣言を収録したヘッダファイルが付属しており, ソースファイルでは, そのヘッダファイルの取り込みを指示するだけで済むようになっている:
#include <ヘッダファイル.h>
これでコンパイル時に,この #include の行が, ヘッダファイルの内容(プロトタイプ宣言)へ置き換えられることになる.
たとえば,printf( ) や scanf( ) といった 標準入出力関数のプロトタイプは, ヘッダファイル stdio.h に記述されている. List 2 を List 3 のように書き換えてみよう.
#include <stdio.h> // printf() と scanf() のプロトタイプ宣言
/* x の逆数 */
double inv(double x)
{
...
}
main()
{
...
printf(...);
scanf(...);
...
}
これをコンパイルすると, これまで発生していた警告メッセージが減ったハズだ. これで,正しいプログラムに一歩,近付いた.
他のよく使うヘッダファイルとしては, stdlib.h,string.h,math.h,等がある. これらのヘッダファイルは,大抵の Unix システムでは, ディレクトリ /usr/include に収められている. どんなものがあるのか,確認してみよう:
$ ls /usr/include | less
ヘッダファイルによっては,プロトタイプ宣言以外の情報も記載されていたり, さらに他のヘッダファイルを取り込んでいたりするので, 実際は,ここでの説明ほど単純なものではない. しかし,それらの内容を眺めておくとよいだろう. たとえば,stdio.h の内容を見るには:
$ less /usr/include/stdio.h
このヘッダファイル内のどこかに, printf( ) や scanf( ) のプロトタイプ宣言が 記述されているハズだ. 検索してみよう.
ライブラリ関数の定義(処理内容)は, 事前にコンパイルされた状態で, オブジェクトファイルに収録されている. したがって,ライブラリ関数を使うプログラムの実行には, ライブラリオブジェクトとのリンク(連結)が必要である.
関数の「宣言」と「定義」とを混同しないこと. 宣言(引数等の型)はヘッダファイル, 定義(処理内容)はオブジェクトファイルに収録されている.
大事なことなので,2回書きました. (が,ソースコードでは,2回も同じことを書かないこと.)
List 4 は数学ライブラリ libm を利用したプログラムの例である.
#include <stdio.h> #include <math.h> // 数学関数のプロトタイプ宣言 main() { double x, y; printf("実数 > "); scanf("%lf", &x); y = sqrt(x); // 平方根 printf("平方根:%f\n", y); }
このソースコードには,エラーはないのだが, 処理系によっては(Linux 等では), これまで通りの方法ではコンパイルできない:
$ cc sqrt.c -o sqrt
/tmp/ccSQVZUd.o: In function `main':
sqrt.c:(.text+0x43): undefined reference to `sqrt' # エラー「sqrt() が定義されてないゼ」
collect2: ld はステータス 1 で終了しました
正しくは,次のコマンドでコンパイルしよう:
文字に注意:「-1(いち)」でなく「-l(エル)」だ.
一般に,ライブラリ libXX をリンクするには, cc コマンドに -lXX を付ける.
これで,数学ライブラリ libm の オブジェクトファイル /lib/libm.so や /lib/libm.a がリンクされ, 実行可能なプログラムファイル sqrt が完成する.
なお,前回までに利用してきたライブラリ関数 (printf( ),scanf( ),等)については, 標準ライブラリ libc に収録されている. そして,この標準ライブラリについては, コンパイル時に -lc を特に指定しなくても, 自動的にリンクされることになっている.
さらに理解を深めるために, ライブラリを作成・利用してみよう.
List 5 および 6 は,統計ライブラリ libstat のソースおよびヘッダである.
#include <stdio.h>
#include <math.h>
#include "stat.h" // このヘッダファイルも自分で作る
// データ入力
int input(double *x, int m)
{
int i, n;
printf("データの個数(%d 個以内) > ", m);
scanf("%d", &n);
printf("%d 個の実数 > ", n);
for (i = 0; i < n; i++) {
scanf("%lf", &x[i]);
}
return (n);
}
// 合計
double sum(double *x, int n)
{
int i;
int s = 0;
for (i = 0; i < n; i++) {
s += x[i];
}
return (s);
}
// 平均
double average(double *x, int n)
{
return (sum(x, n)/(double)n);
}
// 分散 // 未完成(練習問題)
double variance(double *x, int n)
{
double a;
double s = 0.0;
// a = average(...);
// ...
return (s/n);
}
// 標準偏差
double stddev(double *x, int n)
{
return (sqrt(variance(x, n)));
}
// データ入力 int input(double *x, int m); // 合計 double sum(double *x, int n); // 平均 double average(double *x, int n); // 分散 double variance(double *x, int n); // 標準偏差 double stddev(double *x, int n);
まず,これらをコンパイルし,ライブラリオブジェクトを生成しておく:
$ cc -c stat.c -o libstat.a $ ls stat.c libstat.a
List 7 は,このライブラリを利用するテストプログラムである.
#include <stdio.h> #include "stat.h" // 統計ライブラリのヘッダファイルのインクルード main() { double x[256]; int n; n = input(x, 256); // 統計ライブラリの関数の呼び出し printf("平均 = %f\n", average(x, n)); printf("分散 = %f\n", variance(x, n)); printf("標準偏差 = %f\n", stddev(x, n)); }
テストプログラムのコンパイル:
$ cc stattest.c -I. -L. -lstat -lm -o stattest
突然だがここで,関数 scanf( ) についてまとめておく. 一般的な利用形式は次の通り.
scanf(書式文字列, アドレス, アドレス, ...);
主な変換指定子:
ところで,scanf( ) の入力データは, 引数に指定されたアドレスのメモリ領域に記録される. したがって,大抵の場合,引数のアドレスには, 変数へのポインタか文字配列の名前を使うことになる.
使用例:
int i;
double d;
char c;
char s[256];
scanf("%d %lf %c %s", &i, &d, &c, s);
関数 scanf( ) についての詳しくは, 教科書 pp.191-194 を参照しよう.
List 5-7 の分散関数を完成せよ.
ちなみに,分散および標準偏差は,データの分布の広がり度合いの指標である. 詳しくは,4J の授業「確率統計」で学習予定.