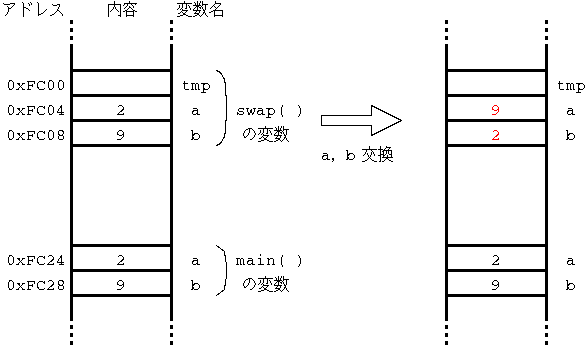
Fig.1 swap-ng.c のメモリマップ
ソースコードを複数個の関数に分割すれば, プログラムを 3C(正確・明解・簡潔)で高品質な形に作りやすい, ということを以前学習した.
今回はさらに,ポインタを利用した関数呼び出しについても理解しよう.
プログラミング言語の一般論として, 関数やサブルーチンの呼び出しのとき,引数の使用方法には, 次の2種類がある:
仮引数として関数内に新たな変数が用意され, 実引数の値が仮引数の変数にコピーされる.
したがって,呼び出された関数内で仮引数の変数値を変化させても, 実引数の変数値は変化しない. (関数の内部での変数値の変更が関数の外部には影響しない.)
したがって,呼び出された関数内で変数値を変化させると, 実引数の変数値も変化する. (関数の内部での変数値の変更が関数の外部にも影響する.)
C言語の場合,関数呼び出しは, すべて,値渡しとして実行される. しかし,ポインタを引数にすれば, 実質的に,参照渡しと同じことになる.
参照渡しを基本としている言語もある. (例:FORTRAN,BASIC)
データ型によって呼び出し方法を切り替えられる言語もある. (例:C++,Java)
Cの関数呼び出しの基本は値渡しとなっている. たとえば:
void func(int x) // 仮引数の x { ... } main() { int x = 1; func(x); // 実引数の x ... }
このコードの仮引数の x と実引数の x とは, 名前と値は同じであるが, 実体は互いに別物である. (同名・別物の変数 x が2個ある.)
このため,値渡しでは, 呼び出された関数内で仮引数を変化させても, 呼び出した側の実引数は変化しない. たとえば,2つの変数 a,b の値を交換するための関数 swap( ) として, List 1 のように定義してもうまく働かない.
/* 変数 a,b の値を交換する関数 */
void swap(int a, int b)
{
int tmp;
tmp = a;
a = b;
b = tmp;
printf("swap : a = %d , b = %d\n", a, b); // テスト出力:関数内での交換後の値
}
main()
{
int a = 2, b = 9;
printf("main : a = %d , b = %d\n", a, b); // テスト出力:交換前の値
swap(a, b);
printf("main : a = %d , b = %d\n", a, b); // テスト出力:交換後の値
}
ちなみに,変数 tmp は, 一時的(temporary)に値を記録しておくためのものだ. 一時変数なしで,たとえば,a = b; b = a; としても 交換にはならない. この場合,a も b も 同じ値(元の b の値)になってしまう.
また,List 1 では,printf( ) が複数の場所に分散しているが, これは,あくまでも実験的なテスト出力のためだ. ふつうの実用的なプログラムでは, 結果出力のための printf( ) を 一箇所(例:main( ) 内だけとか)にまとめて記述すること.
List 1 の実行中のメモリマップの変化の様子を Fig.1 に示す. main( ) 内の変数 a,b と swap( ) 内の変数 a,b は 「名前は同じだけど実体は別物である」 ということに注意しよう. そのため, swap( ) 内で変数値を書き換えても, main( ) 内の変数値は変わらない.
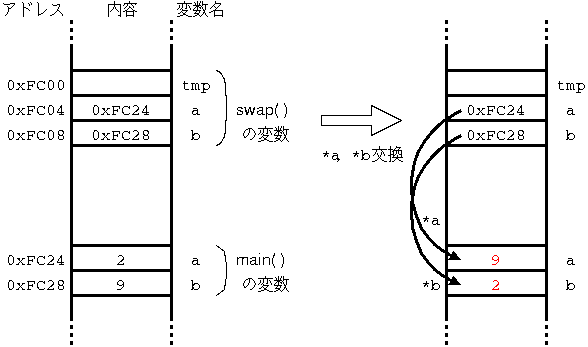
Cで参照渡しを実現するには, 関数の引数を,変数の実体としてではなく, 変数へのポインタとして定義する. List 2 は,List 1 をそのように修正したものだ. このプログラムを実行して, 変数 a,b の値が うまく交換されることを確認してみよう.
/* 変数値 a,b を交換する関数 */
void swap(int *a, int *b)
{
int tmp;
tmp = *a;
*a = *b;
*b = tmp;
printf("swap : a = %d , b = %d\n", *a, *b); // テスト出力
}
main()
{
int a = 2, b = 9;
printf("main : a = %d , b = %d\n", a, b); // テスト出力
swap(&a, &b);
printf("main : a = %d , b = %d\n", a, b); // テスト出力
}
まず,呼び出し側(main() 内の swap() の呼び出し)では, 実引数の変数名に & を付けている. つまり,変数の値ではなく,そのアドレスを実引数としている.
そして,呼び出され側(void swap(...) { ... })では, 仮引数の変数名に記号「*」を付けている. つまり, 実引数に与えられたアドレスを受け取るため, ポインタを仮引数としている.
なお,値交換の処理(たとえば *a = *b)での記号「*」は, 間接参照(ポインタの参照先に記録されているデータ)を 処理の対象とすることを意味している.
List 2 の実行中のメモリマップの変化の様子を Fig.2 に示す. swap( ) 内の処理によって, main( ) 内の変数値を書き換えていることがポイントだ. Fig.2 の左右でのメモリマップの変化に注目しよう. また,Fig.1 とも比較しよう.
なお,一見,参照渡しの方が便利に思えてしまい, 何でも参照渡しにしてしまいたくなるかもしれない. しかし,実際には,値渡しで十分な場合の方が多いハズだ. うまく使い分けること. 本当に必要なときだけ参照渡し, 普段は値渡し.
何でも参照渡しでやろうとすると,場合によっては, 呼び出し側で余計な手順が必要になり, ソースコードの可読性が損なわれる.
ちなみに,参照渡しでは,引数が戻り値を兼ねていることになる. これを利用すれば,実質的に複数個の戻り値をもつ関数も定義できる. (return される本当の戻り値は1個または0個だけだが..., 引数を戻り値として代用する.)
関数 swap( ) を利用した意味のあるプログラムの例として, ソーティング(sorting;並べ替え)プログラムを紹介する. アルゴリズムとしては,単純な選択ソート法を利用する.
List 3 は,その不完全なソースコードである. 省略部分(...)については,各自で補完してみよう.
/* 変数値 *a,*b を交換する関数 */
void swap(int *a, int *b)
{
... // *a と *b を交換
// printf(...); // テスト出力...もう,理解したので不要.削除.
}
/* 配列 data の n 個の要素をソートする関数 */
void sort(int *data, int n)
{
int i, j;
for (i = 0; i < n-1; i++) {
for (j = i+1; j < n; j++) {
if (data[i] > data[j]) swap(data + i, data + j);
// ↑ または,if (...) swap(&data[i], &data[j]); でも同じ
}
}
}
/* 配列 data の n 個の要素を表示する関数 */
void print(int *data, int n)
{
...
}
/* 配列 data に値を入力する関数
* m:最大の要素数
* return:入力した要素数
*/
int input(int *data, int m)
{
int i, n;
printf("データの個数(%d 個以内)> ", m);
scanf("%d", &n); // そうか,scanf( ) も実は参照呼び出しだったんだー
printf("%d 個の整数 > ", n);
for (i = 0; i < n; i++) {
scanf("%d", data + i);
// ↑ または,scanf("%d", &data[i]);
}
return (n);
}
main()
{
int data[100];
int n;
n = input(data, 100);
printf("ソート前:\n");
print(data, n);
sort(data, n);
printf("ソート後:\n");
print(data, n);
}
ところで,関数 sort( ) ,print( ),input() は, 配列 data[100] が引数になっている例だが, 実引数が配列名 data となっているのに対して, 仮引数はポインタ *data となっている. このことは,「配列名は配列の先頭アドレスを表わす」という規則 (説明済み) から理解できるハズだ. つまり, 実引数が配列の場合, 自動的に(有無を言わせず), 参照渡しとなる.
というわけで,List 3 の交換関数 swap() についても, 他の関数と同様,データ配列を引数として, 次のように定義しても良い:
void swap(int *data, int i, int j)
{
... // data[i] と data[j] を交換...
}
省略部分のコードを各自で補完してみよう.
配列が引数になる場合, たとえば sort( ) を次のように定義することも可能: (List 3 の定義方法と比較せよ.)
void sort(int data[100]) // 可能だがよろしくない
{
...
}
これだと,この関数は,引数配列が要素数 100 の場合だけにしか使えないことになり, 再利用性が低いので,あまり良い方法ではない. もちろん,ソースコードを書き換えれば要素数を変更できるが, 定数 100 が複数の場所(main() 内,swap() 内,その他) に重複・散在してしまうので,変更作業が面倒になってしまうし, 作業ミスなどで矛盾が発生する可能性が高い.
必ず次のように,要素数を仮引数にせよ:
void sort(int data[], int n) // 要素数を可変に または void sort(int *data, int n)
この方法であれば, 要素数の異なる複数の配列に対して, ひとつの関数を使いまわすことも可能になる:
int data1[100], data2[256]; ... sort(data1, 100); sort(data2, 256);
以前作成した analyzer.c を 適切に関数分割せよ. (機能ごとに 関数を定義する. 引数について,値渡しと参照渡しとを使い分ける. それぞれの関数には機能にふさわしい名前を付けること.)
関数分割の一例:
ヒント:以前の analyzer.c では, 入力データを各瞬間には1個だけしか記録していなかった. 今回は,すべてのデータを配列に記録しておく必要がある. List 3 を参考にしよう. ただし,入力終了には,List 3 のような事前のデータ数入力ではなく, 以前の analyzer.c のように番兵を使うこと.
注意:
余裕のある人は,さらに機能を拡張してみよう.