Fig.1. 配列要素への間接アクセス
Cをマスターするため (CをCらしく使いこなし,効率的にプログラミングするため) には,ポインタの理解が不可欠だ. 今回は特に,気合いを入れて取り組むこと.
ただし, 前回までの内容を理解していなければ, 今回の内容を理解するのはとても難しい. 復習しながら取り組もう. (特に,前回の内容と強く関連している.)
ポインタ(pointer)は, 他のデータのアドレスを記録するための変数である. ポインタを使うと, 任意のメモリ領域に記録されているデータへ間接的にアクセスできるので, 一個のポインタ変数だけで複数のデータを操作できるようになる. これをうまく活用すれば,効率的なプログラミングが可能となる.
一方,これまで使ってきた通常の変数では,データの値そのものを記録し, データへ直接的にアクセスする. つまり,一個の変数は一個のデータだけしか取り扱えない. 複数のデータを操作したければ, 複数の変数を用意し, それらに対応して, 複数のコードを書く必要がある.
直接アクセス(通常の変数)の場合, たとえば,変数 x は変数 x の値しか読み書きできない. これはまぁ,当たり前だが...
間接アクセス(ポインタ変数)の場合, その変数(ポインタ)は,他のどの変数のデータであっても読み書きできる. たとえば, 複数個の変数 x,y,z とか 複数の配列要素 a[0],a[1],a[2] の値を1個のポインタ変数 p だけを使って読み書きできる.
では,List 1 を試してみよう. これは,1個のポインタ p で 2個の変数 a,b を間接的に操作するプログラムである.
main()
{
int a=1, b=2;
int *p; // ポインタの宣言
printf("初期値: a = %3d , b = %3d\n", a, b);
p = &a; // a のアドレスを代入(a を参照)
*p = 100; // a への間接的な代入
printf("結果1: a = %3d , b = %3d\n", a, b);
p = &b; // b のアドレスを代入(b を参照)
*p = 200; // b への間接的な代入
printf("結果2: a = %3d , b = %3d\n", a, b);
}
実行結果:
$ ./ptr1 初期値: a = 1 , b = 2 結果1: a = 100 , b = 2 # *pに代入したハズなのに? 結果2: a = 100 , b = 200 # 〃
ソースコードでは,p 以外の変数については, 書き換えていないように見える. しかし実際には, 変数 a や b の値が書き換えられている. これがポインタによる間接アクセスの効果だ.
なお,ポインタがアドレスを記録している状態について, そのアドレスにあるデータを「参照している」 or「指して(さして)いる」と言う.
また,ポインタ変数を宣言するときには, 変数名の前にポインタ宣言子「*」を付ける. また,参照先(そのアドレスに記録されているデータ) にアクセスするときにも, 同じ記号の間接演算子「*」を使う.
一旦,話題を変えます...
List 2 を実行し, データの種類によるメモリ領域の大きさの違いについて, 確認しておこう.
main()
{
char vc, *pc; // char 型の通常変数と char 型へのポインタ
int vi, *pi; // int 型の通常変数と int 型へのポインタ
double vd, *pd; // double 型の通常変数と double 型へのポインタ
printf("[通常変数のデータサイズ]\n");
printf("sizeof(vc) = %d\n", sizeof(vc));
printf("sizeof(vi) = %d\n", sizeof(vi));
printf("sizeof(vd) = %d\n", sizeof(vd));
printf("\n");
printf("[ポインタのデータサイズ]\n");
printf("sizeof(pc) = %d\n", sizeof(pc));
printf("sizeof(pi) = %d\n", sizeof(pi));
printf("sizeof(pd) = %d\n", sizeof(pd));
printf("\n");
printf("[ポインタの参照先のデータサイズ]\n");
printf("sizeof(*pc) = %d\n", sizeof(*pc));
printf("sizeof(*pi) = %d\n", sizeof(*pi));
printf("sizeof(*pd) = %d\n", sizeof(*pd));
}
実行結果:
$ ./size [通常変数のデータサイズ] sizeof(vc) = 1 # char 型 → 1 byte sizeof(vi) = 4 # int 型 → 4 byte sizeof(vd) = 8 # double 型→ 8 byte [ポインタのデータサイズ] sizeof(pc) = 8 # char 型へのポインタ sizeof(pi) = 8 # int 型へのポインタ sizeof(pd) = 8 # double 型へのポインタ [ポインタの参照先のデータサイズ] sizeof(*pc) = 1 # char 型 sizeof(*pi) = 4 # int 型 sizeof(*pd) = 8 # double 型
解説:
これは,以前説明した通りだ.
なぜなら,ポインタは,どの型であっても, 同じ種類のデータ(== アドレス値)を記録する変数であるからだ.
List 1 のプログラムの実行中,一体,メモリマップ内でどんな変化があったのか? 次に,List 3 のプログラムを利用して,詳しく調べてみよう. これは,List 1 を元にして,アドレス表示などを追加したものである.
main()
{
int a=1, b=2;
int *p;
printf("[初期状態のメモリマップ]\n");
printf("&a = 0x%08X : a = %d\n", &a, a);
printf("&b = 0x%08X : b = %d\n", &b, b);
printf("&p = 0x%08X : p = 0x%08X\n\n", &p, p); // pの値はゴミ
printf("[ポインタ p による変数 a への間接操作]\n");
p = &a; // a を参照
printf("p = 0x%08X\n", p); // a のアドレスを表示
printf("*p = %d\n", *p); // a の値を表示
*p = 100; // a の値を書換
printf("*p = %d\n\n", *p); // a の値を表示
printf("[a の間接操作結果のメモリマップ]\n");
printf("&a = 0x%08X : a = %d\n", &a, a);
printf("&b = 0x%08X : b = %d\n", &b, b);
printf("&p = 0x%08X : p = 0x%08X\n\n", &p, p);
printf("[ポインタ p による変数 b への間接操作]\n");
p = &b; // b を参照
printf("p = 0x%08X\n", p);
printf("*p = %d\n", *p);
*p = 200; // b の値を書換
printf("*p = %d\n\n", *p);
printf("[b の間接操作結果のメモリマップ]\n");
printf("&a = 0x%08X : a = %d\n", &a, a);
printf("&b = 0x%08X : b = %d\n", &b, b);
printf("&p = 0x%08X : p = 0x%08X\n\n", &p, p);
}
特に,p と *p のちがいに注意.
それと,実験室の PC は 64bit OS なので, ポインタのサイズは実際には 8 byte(16進数で16桁)ではあるが, ちょっと長すぎるので,この授業では, 変換指定子 %08X によって 下位の 4 byte 分(16進数で8桁)だけを表示している. (フルに 8 byte 分を表示したければ変換指定子 %016lX を使えばよい.)
実行例:(ソースコードと実行結果とを注意深く比較・観察しよう.)
$ ./ptr2 [初期状態のメモリマップ] &a = 0xBFC738E4 : a = 1 &b = 0xBFC738E0 : b = 2 &p = 0xBFC738D8 : p = 0xXXXXXXXX # p の値は初期化していないのでゴミ # a, b, p は異なるメモリ領域を使用(p の値は初期化していないのでゴミ) [ポインタ p による変数 a への間接操作] p = 0xBFC738E4 # p は a を参照している(p = &a) *p = 1 # *p は a と同体なので... *p = 100 # *p を書き換えると... [a の間接操作結果のメモリマップ] &a = 0xBFC738E4 : a = 100 # ... a の値が変わる &b = 0xBFC738E0 : b = 2 &p = 0xBFC738D8 : p = 0xBFC738E4 # a, b, p のアドレスは不変 [ポインタ p による変数 b への間接操作] p = 0xBFC738E0 # (b については自分で考えてみよう) *p = 2 *p = 200 [b の間接操作結果のメモリマップ] &a = 0xBFC738E4 : a = 100 &b = 0xBFC738E0 : b = 200 &p = 0xBFC738D8 : p = 0xBFC738E0
この実行例におけるメモリマップは Table 1 の通りである. メモリ内のデータ値がプログラムの実行中に変化していることに注意しよう. List 1 と実行例と Table 1 とをよく比較してみよう.
| アドレス範囲 | 変数名 | 初期値 | →a操作後の値 | →b操作後の値 |
|---|---|---|---|---|
| 0x BFC7 38D8 〜 38DF | p | ゴミ | →0x BFC7 38E4 | →0x BFC7 38E0 |
| 0x BFC7 38E0 〜 38E3 | b | 2 | 2 | →200 |
| 0x BFC7 38E4 〜 38E7 | a | 1 | →100 | 100 |
ところで,ポインタも変数の一種なので, 通常の変数と同様に,ポインタもデータ型をもつ. 通常は,参照先のデータの型と参照元のポインタの型とを一致させる必要がある. たとえば, 次のソースコード断片は間違い:
int a; double *p; p = &a; // 型が違うのでダメ
なお,コンパイル時にはエラーではなく警告(warning)が発生するだけなので, 型が一致していなくても実行できてしまう. しかし,この場合,実行はできても,その結果が意図した通りになるとは限らない.
Cでは,配列名自身が先頭要素のアドレスを表わすことになっている. たとえば,配列要素 a[0] のアドレスについては,a とだけ書けばよい. 長たらしく &a[0] と書く必要はない.
また,配列のメモリ領域については, 前回確認した通り, 配列のすべての要素のアドレスは連続している.
つまり,これらのことから,配列の各要素のアドレスを調べるには, 実は,アドレス演算子「&」を使う必要はまったく無い. List 4 のプログラムを実行し,確認してみよう.
main()
{
int a[3];
printf("%x %x\n", &a[0], a); // 先頭アドレス
printf("%x %x\n", &a[1], a+1); // 1 番目の要素のアドレス
printf("%x %x\n", &a[2], a+2); // 2 番目の要素のアドレス
}
実行結果からわかる通り, &a[i] と a+i とは, まったく等価である. これからは,配列のアドレス計算には, & を使わず,短かく書くとよい.
それと,ソースコードでは +1 とか +2 したハズなのに, 実行結果ではなぜか,+4 とか +8 になってしまっている. この謎については,本日の練習問題とする.
配列の名前がアドレス値であり, また,アドレスの変数がポインタだった. すると当然,配列とポインタの間にも大きな関連性がある. List 5 のプログラムを実行してみよう.
main()
{
int a[5] = { 0, 1, 4, 9, 16 }; // 配列
int *p; // ポインタ
int i;
for (i = 0; i < 5; i++) { // 配列への直接アクセス
printf("a[%1d] : %d\n", i, a[i]);
}
printf("\n");
p = a;
for (i = 0; i < 5; i++) { // 間接アクセス方法 #1
printf("p[%1d] : %d\n", i, p[i]);
}
printf("\n");
p = a;
for (i = 0; i < 5; i++) { // 間接アクセス方法 #2
printf("*(p+%1d) : %d\n", i, *(p+i));
}
printf("\n");
p = a;
for (i = 0; i < 5; i++) { // 間接アクセス方法 #3
printf("*p : %d\n", *p);
p++;
}
printf("\n");
}
このように,配列要素へアクセスするには様々な方法がある. ここでは,特に重要な「間接アクセス方法 #3」の仕組を解説しておく:
これは,p = &a[0]; と同じことだが, アドレスの足し算(a+0)を計算しない分だけ, より効率的に(少ない計算量で)実行している.
これは,a[i] や p+i と同じことだが, アドレスの足し算(a+i)を計算しない分だけ,より効率的.
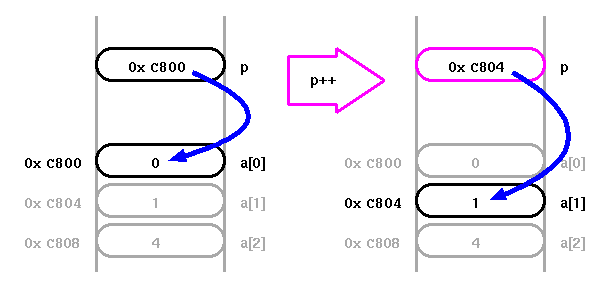
再度 p++ すれば,さらに次の a[i+2] を指すことになる.
実は,List 5 のように単純すぎる処理の場合, どの方法でも効率は大して変わらない. たとえば,方法#3 では, アドレスの足し算 a+i が不要になった一方, p++ が余分に必要となっていた.
しかし,より複雑な処理の場合, 同じ要素 a[i] に触る回数が増えるほど,効果も増す. たとえば,直接アクセス a[i] を n 回書くと, アドレス計算も n 回必要になる. 一方,関節アクセス *p なら何度書いても, アドレス計算は p++ の分の1回だけで済む.
「チリも積もれば山となる.」 特に,最近話題のビッグデータの処理では,処理効率(計算速度)が重要. せっかく高性能なコンピュータがあっても, プログラムの効率が悪いと,台無しだ.
また,Fig.1 は,この方法 #3 でのメモリマップの変化のイメージである.
[教科書 pp.119-120]
List 5 や Fig.1 は,ひとつのポインタ変数 p によって, 複数の変数データ a[0],a[1],…,a[4] にアクセスできることを示している. つまり,「ポインタ=変数名を記憶する変数(変数の変数)」という考え方でも良い. (値を変えれば他の変数にアクセスできるような変数.)
しかしポインタは,実は,変数名の付けられていないメモリ領域にもアクセスできる. なのでやはり,「ポインタ=アドレスを記憶する変数」という考え方がより正しい. (無名メモリ領域については,後日どこかで説明したい.)
文字配列を使ってみよう. List 6 のプログラムは, 文字列をキーボードから入力し, char 型の配列に代入し, 画面に表示している. 本日の課題では,これを元にして,ポインタの練習プログラムを作成する.
main()
{
char str[10];
printf("文字列(9 文字以内) > ");
scanf("%s", str); // 文字列の入力
printf("str = \"%s\"\n", str); // 文字列の表示
}
なお,List 6 では,文字「"」自体を表示するために, エスケープ系列「\"」を使用している. 単独の文字「"」は特殊記号(文字列の開始・終了記号)であるため, そのままでは,文字列の途中では使えない. また,「%s」は,文字列の入力と表示の変換指定子である.
ただし,次の条件を満たすこと:
char str[20]; int n; ... n = strlen(str);
実行例:
$ ./tategaki 文字列 > programming p r o g r a m m i n g