開発中のグラフィックスインタプリタ cg.c では, ソースコードが随分と長くなってきた. 今回は,単独の大きなソースファイルを 複数の小さなソースファイル群へ分割する方法を修得しよう.
今回は,いつもより多数のファイルを作成する. 各プログラムごとにディレクトリを用意し, そのディレクトリの中で作業することを強く推奨する.
今回,課題はないが,作業は多くある. 置き去りにされないように! (次回は,今回の作業結果を使う課題がある予定.)
まず,List 1 の統計処理プログラム calcstat を例として, ソースファイルの基本的な分割方法を説明する. このセクションでは,ディレクトリ calcstat-1 を作り, その中で作業することを推奨.
$ mkdir calcstat-1 $ cd calcstat-1
/****************************************************
統計処理プログラム
実数データを標準入力し,平均と標準偏差を表示する.
****************************************************/
#include <stdio.h>
#include <stdlib.h>
#include <math.h>
#define SIZE 10000 // データ配列の最大サイズ
int data_error = 0; // 入力データのエラーコード(グローバル変数)
/* 合計を計算する関数 */
double Sum(double x[], int n)
{
int i;
double s = 0.0;
for (i = 0; i < n; i++) {
s += x[i];
}
return (s);
}
/* 平均を計算する関数 */
double Average(double x[], int n)
{
return (Sum(x, n)/n);
}
/* 標準偏差を計算する関数 */
double StdDev(double x[], int n)
{
int i;
double a, d, s = 0.0;
a = Average(x, n); // 平均
for (i = 0; i < n; i++) {
d = x[i] - a; // 偏差
s += d*d; // 偏差自乗和
}
return (sqrt(s/n));
}
/* ファイルからデータを入力する関数 */
int ReadData(FILE *fp, double x[], int size)
{
int n, c;
for (n = 0; n < size; n++) {
c = fscanf(fp, "%lf", &x[n]);
if (c != 1) break;
}
if (c == 0) data_error = 1; // 異常なデータ
else if (n == 0) data_error = 2; // データなし
else if (n >= size) data_error = 3; // 配列サイズ不足
return (n);
}
/* 入力データのエラー処理 */
void DataError(int n)
{
char *msg;
switch (data_error) {
case 1: msg = "データが変です."; break;
case 2: msg = "データありません."; break;
case 3: msg = "データ多すぎです."; break;
default: msg = "なんか変です.";
}
fprintf(stderr, "データ %d 番:%s\n", n, msg);
exit (EXIT_FAILURE);
}
int main()
{
double x[SIZE];
int n;
n = ReadData(stdin, x, SIZE);
if (data_error != 0) DataError(n);
printf("平 均:%f\n", Average(x, n));
printf("標準偏差:%f\n", StdDev(x, n));
return (EXIT_SUCCESS);
}
$ cc calcstat.c -lm -o calcstat
$ cat > data.txt
20
15
30
...
[Ctrl]+[D]
$ ./calcstat < data.txt
平 均:...
標準偏差:...
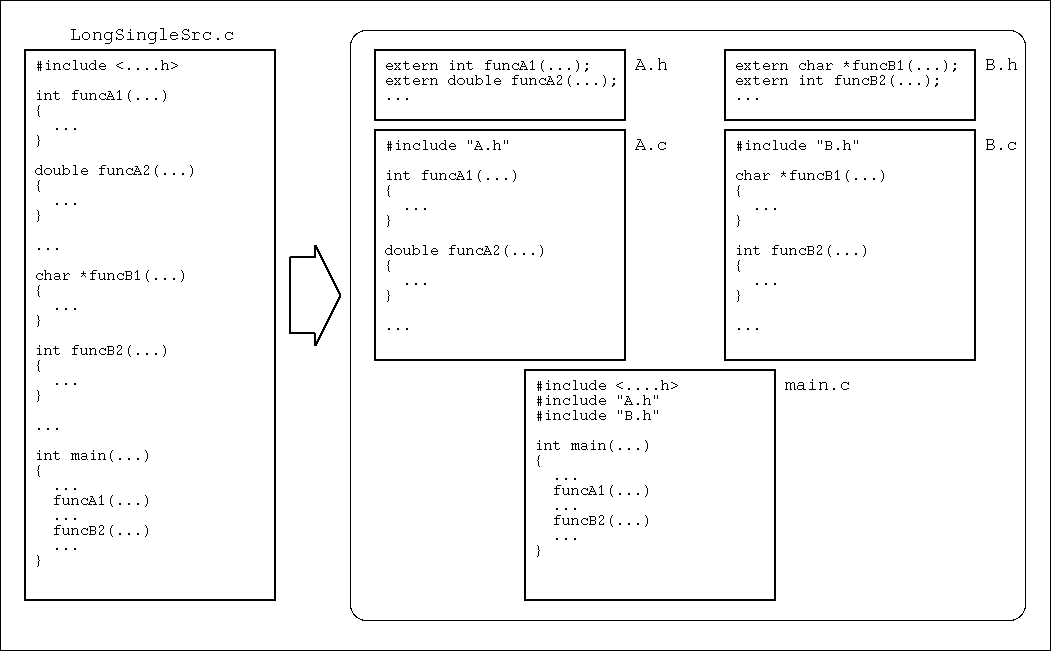
C言語では, List 1 のような単独ソースファイルのプログラムを, List 2 のように複数のファイルへ分割して記述できる. List 1 のソースファイルを元にして, List 2 (a)-(c) の各ファイルを作成してみよう. (関数の内部は List 1 とまったく同じ.関数の外部だけが少しだけ異なる.)
ソース分割(List 2)の準備作業の例:
$ cp calcstat.c main.c # 同一内容のファイルを3個作成 $ cp calcstat.c input.c $ cp calcstat.c func.c $ ls calcstat.c input.c func.c main.c $ vi main.c # コードの修正(重複部分の削除等) $ vi input.c $ vi func.c
/****************************************************
統計処理プログラム
実数データを標準入力し,平均と標準偏差を表示する.
****************************************************/
#include <stdio.h>
#include <stdlib.h>
#define SIZE 10000 // データ配列の最大サイズ
// 外部変数の型宣言
extern int data_error;
// 外部関数のプロトタイプ宣言(extern は省略可)
extern double Average(double x[], int n);
extern double StdDev(double x[], int n);
extern int ReadData(FILE *fp, double x[], int size);
extern void DataError(int n);
// 行末のセミコロン「;」忘れやすい
int main()
{
... // 関数の定義内容には変更なし
}
#include <stdio.h>
#include <stdlib.h>
// グローバル変数の定義
int data_error = 0; // 入力データのエラーコード
/* ファイルからデータを入力する関数 */
int ReadData(FILE *fp, double x[], int size)
{
... // 変更なし
}
/* 入力データのエラー処理 */
void DataError(int n)
{
... // 変更なし
}
#include <math.h>
// 内部関数のプロトタイプ宣言(関数定義の順序次第では省略してもよい)
double Average(double x[], int n);
double StdDev(double x[], int n);
double Sum(double x[], int n);
/* 平均を計算する関数 */
double Average(double x[], int n)
{
... // 変更なし
}
/* 標準偏差を計算する関数 */
double StdDev(double x[], int n)
{
... // 変更なし
}
/* 合計を計算する関数 */
double Sum(double x[], int n)
{
... // 変更なし
}
List 2 をコンパイルするには,次の2通りの方法がある:
$ cc main.c input.c func.c -lm -o calcstat
$ cc -c main.c # ソース main.c をコンパイルしオブジェクト main.o を生成 $ cc -c input.c # 〃 input.c を 〃 input.o を生成 $ cc -c func.c # 〃 func.c を 〃 func.o を生成 $ cc main.o input.o func.o -lm -o calcstat # オブジェクトを連結して実行形式ファイルを生成
実行結果は単独ソースの場合とまったく同じハズだ. 確認しよう.
コンパイルの際(オブジェクトの連結の場合ではなく,ソースのコンパイルの場合), 正式には,-Wall も指定すること. ただし,一括コンパイルの場合, (ファイルの個数に比例して)大量のエラー・警告が発生し, 収拾がつかなくなってしまうかもしれない.
そこで,まず最初は -Wall なしでコンパイルし, 重大なエラーだけを見つけ、修正しよう. その後で -Wall し, 軽微なエラーを修正するのが得策だろう.
ソースファイルやコンパイルを分割することは, ただ面倒を増やしているだけに見えるかも知れない. しかし,大規模なプログラムを開発する場合には, 次のように,多くのメリットがある:
さて,List 2 に関連して,次の概念についても理解しておこう:
なお,List 2(c) 内の関数の順序は List 1 の順序から意図的に変えられている. Average( ) で Sum( ) を呼び出しているが, プロトタイプ宣言がない場合, Sum( ) の型がわからないのでコンパイルエラーになる: (プロトタイプ宣言の部分をコメントにして試してみよう.)
// double Sum(...); // プロトタイプ宣言がないと... double Average(...) { ... Sum(...) ... // コンパイルエラー!! } ... double Sum(...) // 使う前に宣言しとかなきゃ... { ... }
一方,List 1 のように Sum( ) を Average( ) の前に定義すれば, 問題無くコンパイルできる. この場合,定義が宣言を兼ねているわけだ.
これまではこの方法を採り,プロトタイプ宣言を省略してきた. 一方,常にプロトタイプ宣言を記述しておくようにすれば, 関数の定義順序を気にせずに済む.
なお,定義と宣言のちがいがわかるだろうか? 答は後述.
List 2 の分割ソースファイルでは, 同じプロトタイプ宣言が複数のファイルに分散していた. たとえば,Average( ) と StdDev( ) の宣言が main.c と func.c の両方にある.
より大規模なプログラムでは,当然, 複数のファイルに共通した記述が, より多く必要になる. しかし,プログラマの立場から見ると, 何度も同じことを書くのは, 単に面倒なだけでなく, 入力ミスの元凶でもあり, 回避すべきである.
この問題を解決するのがヘッダファイルである. ヘッダファイルは, 複数のソースファイルで共通する(かもしれない)コード (プロトタイプ宣言や構造体定義など)だけを記述したものだ. 各ソースファイルでは,共通する宣言等を個別に重複して記述する必要はなくなり, それらのヘッダファイルをインクルードするだけで済む.
List 3 がヘッダファイルを利用した例である. List 2 を元にして,List 3 を作ろう. なお,List 2 では, プロトタイプ宣言等を各ソースファイル *.c に記述していたが, List 3 では,それらを別のヘッダファイル *.h に分離している.
ヘッダ分割(List 3)の準備作業の例:
$ pwd /.../calcstat-1 # 今いる場所を確認 $ cd .. $ cp -r calcstat-1 calcstat-2 # ディレクトリをコピー $ cd calcstat-2 $ ls calcstat.c data.txt input.c func.c main.c $ rm calcstat.c $ cp input.c input.h $ cp func.c func.h $ lscalcstat.cdata.txt input.c input.h func.c func.h main.c
/****************************************************
統計処理プログラム
実数データを標準入力し,平均と標準偏差を表示する.
****************************************************/
#include <stdio.h>
#include <stdlib.h>
#include "input.h"
#include "func.h"
#define SIZE 10000 // データ配列の最大サイズ
int main()
{
...
}
#include <stdio.h> // FILE 型に必要
extern int data_error;
extern int ReadData(FILE *fp, double x[], int size);
extern void DataError(int n);
#include <stdio.h>
#include <stdlib.h>
#include "input.h"
int data_error = 0; // 入力データのエラーコード
/* ファイルからデータを入力する関数 */
int ReadData(FILE *fp, double x[], int size)
{
...
}
/* 入力データのエラー処理 */
void DataError(int n)
{
...
}
extern double Average(double x[], int n); extern double StdDev(double x[], int n); extern double Sum(double x[], int n);
#include <math.h>
#include "func.h"
/* 平均を計算する関数 */
double Average(double x[], int n)
{
...
}
/* 標準偏差を計算する関数 */
double StdDev(double x[], int n)
{
...
}
/* 合計を計算する関数 */
double Sum(double x[], int n)
{
...
}
コンパイル方法は List 2 の場合とまったく同じだ. 再度,コンパイルと実行を試してみよう.
ところで,実用的なプログラムでは,構造体がよく利用される. このようなプログラムのソースを分割する場合, 構造体定義についてもヘッダファイルに記述することになるが, 特別な注意が必要である. ヘッダファイルは複数回インクルードされる可能性があるためだ.
たとえば,apple.c から apple.h と fruit.h をインクルードしたところ, fruit.h も apple.h をインクルードしていた, みたいな場合がある. この場合,apple.c をコンパイルすると, apple.h は 2 回インクルードされることになる. もし,apple.h で構造体を定義していると, 同名の構造体が二重に定義されることになり, これはコンパイルエラーとなる.
構造体定義は,二重に実行しちゃダメ. 一方,extern 宣言は,二重に実行しても問題ない.. 「宣言」と「定義」の違いがわかるだろうか?
定義では,何らかの情報をメモリ内に作成する. たとえば,変数のメモリ領域を確保し,初期値を代入する,等. コンピュータ内では,同じ名前のものを一度しか作れない. 同じ名前のものを作ると区別できないので禁止. 同じものを何度も作るのは無駄だし... てことで,定義するのは1回だけ. (もちろん,スコープが異なる場合は,同じ名前でも OK.)
宣言では,定義済み(作成済み)の情報を伝達・共有するだけ. いうなれば「お知らせ」? 実社会では,同じ情報を1回だけでなく,何度かお知らせすることがよくある. 実際,何度もされるとウザいんだが...0回だと困る,みたいな. てゆーわけで,宣言するのは1回以上.
ただし,この話は,複数のソースファイルにまたがる物の場合だけに限る. ローカル変数とかだと定義と宣言とが一体化していたりするので, 宣言・定義は合わせて1回だけになる.
これを避けるために, インクルードガード(include guard)という技がある. たとえば,ヘッダファイル header.h で 構造体型 Record を定義する場合,次のようにすればよい:
#ifndef HEADER_H // フラグが立っていなければ( if HEADER_H is not defined ) { #define HEADER_H // フラグを立てる( define HEADER_H ) typedef struct { // 構造体を定義 { int member1; int member2; } Record; // } #endif // }
こうすれば,このヘッダファイルが複数回インクルードされても, typedef は1回だけしか実行されない. なお,このときのフラグ(マクロ)は, 半角英大文字でヘッダファイルまたは構造体と似た名前を付けておくのが お約束となっている. これは,フラグ名の重複を避けるためだ.
フラグ名をすべて HEADER_H にしてしまう人が稀にいる...orz. たとえば,ヘッダファイル pbm.h ならばフラグ PBM_H とかにしよう.
また,インクルードガードは,構造体定義だけにしか使えない, という訳ではない. ヘッダファイル全体をガードしてもよい. 安全のため(余計な悩みを減らすため,いつでも,構造体定義がなくても), すべてのヘッダファイルでファイル全体をガードしておく, という流儀もある.
グラフィックスインタプリタ cg.c を 複数のソースファイルおよびヘッダファイルへ適切に分割せよ.
ヒント:
ソースファイルおよびヘッダファイルの分類のコツ:
今回の実験では,ソースファイルがかなり大きくなってから分割する, という開発方法を採用した. このため,分割作業は非常に面倒になってしまったかもしれない. 本来ならば,肥大化しすぎる前に, あらかじめ,こまめに,分割作業をしておくべきだ.
普通の大規模プロジェクトでは,開発作業の効率化のため, 最初から(大きくなることを予想して) 複数のソースファイルとして作り始める, という開発方法を採用することになるハズ. ま,予想以上に肥大化してしまった場合には, やはり分割作業が追加で必要になってくるのだが... 面倒なので分割せず,そのまま続行してしまうと, 肥大化が加速し,かえって面倒が増えることになるだろう.
参考:ファイル分割のイメージ図
{kind=link}